
В сфері ІТ та управлінні послугами ITSM (за ITIL) «Інцидент» - це будь-яка подія, яка не є частиною стандартної роботи сервісу та призводить (або може призвести) до перебою в роботі або зниження якості послуги.
Incident Management (Управління інцидентами) — це процес (Практика в ITIL v4), спрямований на максимально швидке відновлення нормальної роботи сервісу після збою з мінімальним негативним впливом на бізнес-процеси.
Згідно з методологією ITIL, головна мета цього процесу — не знайти причину (цим займається Problem Management), а саме відновити працездатність.
RFI - (Request For Incident) - Запит по інциденту.
Базовий тип запиту в системі ServiceDesk, що зазвичай складається із 2 об’єктів:
Форма запиту (Документ) - фіксує факт такої події, її прояви, час її виникнення (чи хоча б виявлення), користувача, у якого трапилась подія або систему моніторингу, яка її виявила по відхиленю параметрів сервісу.
Робочій процес (Діаграма) - послідовність етапів (дій, задач, перевірок) та правил залучення фахівців та їх команд для вирішення інциденту в бажані терміни (SLA).
Багато компаній і підрозділів починають автоматизацію своїх IT процесів саме з інцидентів. Воно і зрозуміло. Непрацюючий сервіс - найбільша шкода бізнесу. Швидке вирішення і відновлення - мотивація і впевненість користувачів робити свою роботу краще.
З досвіду: чим менше користувачів, систем, та фахівців з підтримки, тим простіше може бути процес вирішення інцидентів. Це не впливає на швидкість і якість підтримки.
“Простий інцидент” (Simple incident) - може бути оптимальним процесом для роботи декількох спеціалістів в підтримці кількох десятків користувачів.
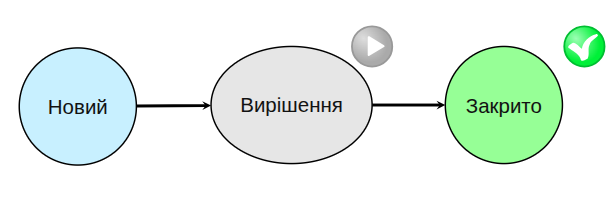
Але якщо користувачів і систем більше, кількість та різномаїття випадків зростає. Для процесування і вирішення таких інцидентів потрібен складніший процес:
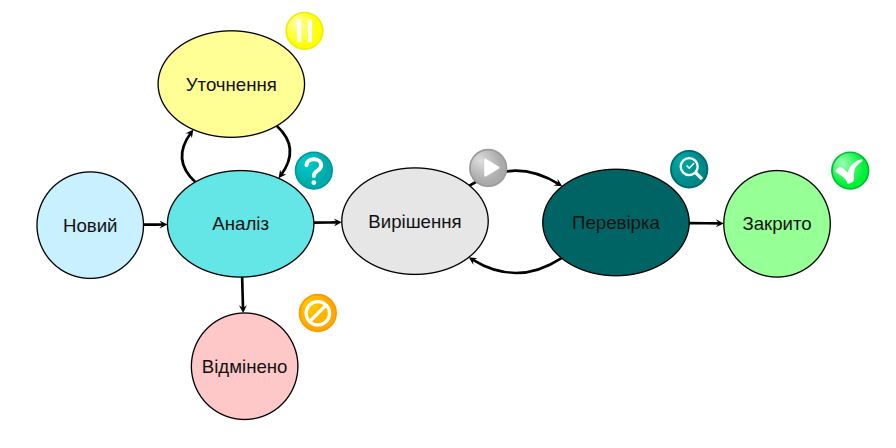
Дуже негативною є практика реєстрації всіх видів запитів до служби підтримки як інцидент, а після аналізу частина перекваліфікується в запити на обслуговування, консультації, доступ, на зміни тощо.
Такий підхід не дає розуміння саме частоти і періодичності трапляння інцидентів з тим чи іншим сервісом. В подальшому це ускладнює процес покращення якості сервісу чи пошуку проблем. На практиці багато замовників наполягають на єдиній формі і на універсальному процесі спілкування з користувачами. Такий підхід не дає розуміння саме частоти і періодичності трапляння інцидентів з тим чи іншим сервісом. В подальшому це ускладнює процес покращення якості сервісу чи пошуку проблем. На практиці багато замовників наполягають на єдиній формі і на універсальному процесі спілкування з користувачами.
Особливо це розповсюджено, коли канал спілкування один: електронна пошта чи віконце створення простого “тікета” в сторонній системі. Наполегливо рекомендую назвати такі запити наприклад “Звернення” чи “Простий Запит”. Особливо це розповсюджено, коли канал спілкування один: електронна пошта чи віконце створення простого “тікета” в сторонній системі. Наполегливо рекомендую назвати такі запити наприклад “Звернення” чи “Простий Запит”.
Чому ж автоматизація IT починається та часто нажаль закінчується :( саме на інцидентах?
Управління інцидентами — це не просто «гасіння пожеж». Це мистецтво повернення бізнесу до життя з мінімальними втратами. Але є кілька нюансів, про які часто забувають:
Масштаб має значення: для маленької команди «Simple Incident» — це ідеально. Для великих ентерпрайзів потрібні складні процеси та жорсткі правила ескалації та SLA.
Пастка «Універсального тікета»: Називати все підряд інцидентом — шлях до хаосу. Якщо ви не розрізняєте аварію та запит на консультацію, ви ніколи не побачите реальну частоту збоїв у ваших сервісах.
Термінологічна гігієна: Привчайте користувачів до терміну «Звернення» або «Запит», залишаючи «Інцидент» для реальних технічних відхилень.
Це і є професійний підхід до ITSM.